
AI Has Been A Race to the Bottom, Towards Alignment
Throughout 2025, misalignment scores fell for many AI labs even as capabilities climbed.

ICYMI, I got married to Charlotte Dreizen this weekend. As I said during the ceremony, “These vows today are partly a formality because you and I are already living a committed love.” It was months of planning for a day that went all too quickly. But I am back at work and ready to get back into it.
Last week, I was at the University of Chicago talking about all things AI. After the panel, I struck up a conversation with an audience member who worried that frontier AI companies were racing to the bottom when it comes to AI safety. What he meant is that the competition to release more capable models might create pressure to skimp on testing.
I think he was right but not for the reasons he imagines. AI has been involved in a race to the bottom, but it’s been towards more alignment. The competitive pressure to release new models has also created powerful incentives to build better alignment tools.
Indeed, AI is unique in that it is spawning a new class of models to make the tech better. The Petri auditor agent, for example, subjects a target model to realistic, multi-turn scenarios and tries to elicit deception, misuse, sycophancy, sabotage, and a range of other misaligned behaviors. A separate judge model then scores the interaction. Jan Leike, lead of alignment at Anthropic, explained the power of these auditor models: “for the first time we have an alignment metric to hill-climb on. It’s not perfect, but it’s proven extremely useful for our internal alignment mitigations work.”
Results from the Petri auditor agent showed a striking trend over 2025. Models got substantially more aligned as misalignment dropped. Anthropic wasn’t the only AI company doing better. Google and OpenAI have also made significant progress. xAI is a different story altogether.
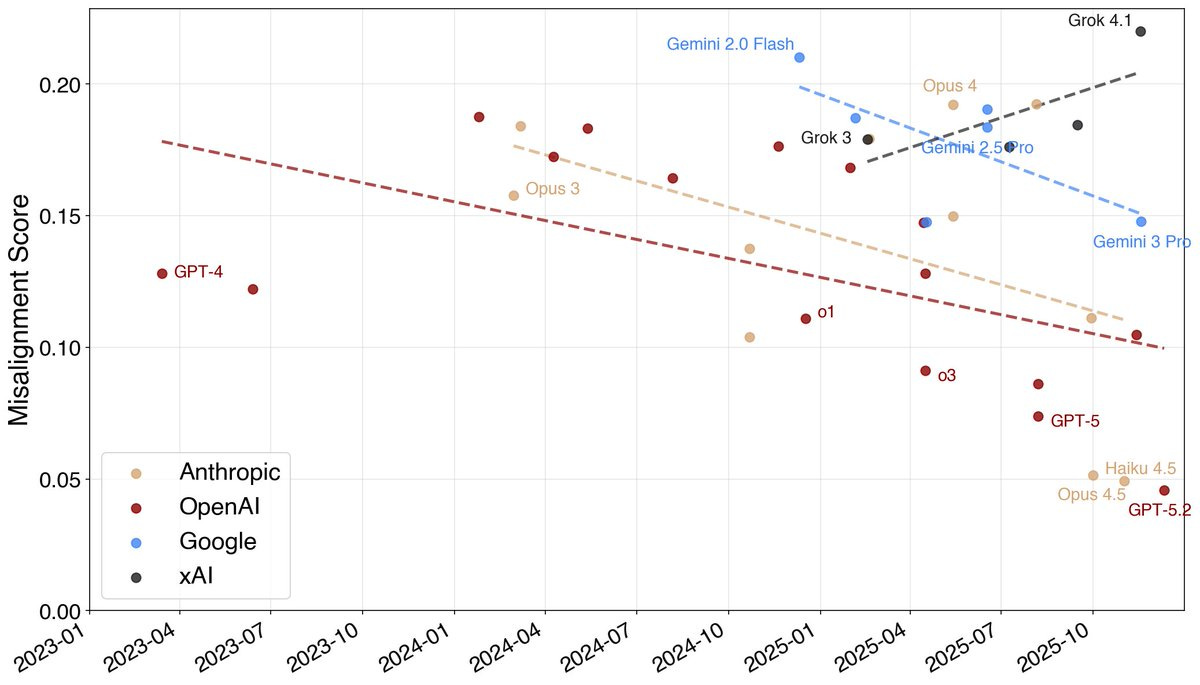
Alignment is hard and incomplete, to be sure, but the major labs are making progress. As Jan Leike explained in a post titled “Alignment is not solved: But it increasingly looks solvable,” the scale-up is “by no means finished, but at this point we have some solid evidence that we can manage these misalignments while scaling up.”
I’ve written before about Aaron Wildavsky’s core argument in Searching for Safety, that safety is “largely an unknown for which society has to search.” A policy or intervention might make us safer, or it might not. Often, he wrote, we only learn which is which after the fact. The same is true of AI. Safety is sought by searching for it, by building systems, probing them, auditing them, red-teaming them, and learning.
Wildavsky drew a distinction between strategies of resilience and anticipation. Anticipatory strategies try to predict and prevent harm before it occurs while resilient strategies build the capacity to absorb shocks. Wildavsky’s bet was on resilience because it compounds. Each correction adds to a stock of knowledge that makes the next correction easier and faster.
Aaron Wildavsky’s insights on risk seem to be holding.
The open question is whether that loop can keep pace with capability gains, especially with tech like Anthropic’s Mythos. Misalignment scores fell sharply in 2025 even as model capabilities rose, which is an encouraging trend. But the relationship between capability and misalignment risk is not linear and there’s no guarantee the trend will hold at the next order of magnitude of capability. Still, Wildavsky’s insights are powerful as they encourage us to continue the search and build better detection. He would also say that stopping the search, on the grounds that the next step might be dangerous, forfeits the knowledge needed to manage that danger.
If the future is radically uncertain, then the rational response is not to obsess over unconditional doom forecasts. It is to look for variables we can actually move. Automated auditing is valuable precisely because it turns alignment into something like an engineering target. The real race, then, is not to abandon the search for safety, but to learn fast enough to keep alignment ahead of capability.
Until next time,
🚀 Will
Another excellent piece. Completely coincidentally, I agree with you completely!
"Safety is sought by searching for it, by building systems, probing them, auditing them, red-teaming them, and learning." Exactly. That understanding is embodied in the Proactionary Principle, in sharp contrast to the precautionary principle. Also, good to see a mention of Wildavsky.
Congrats on getting married! I'm worried about tail risks related to malicious use, but I'm generally in alignment with what you're saying - aligment and capabilities go together, and companies have a very strong incentive to focus on safety, and that is exactly what we're seeing at the major AI labs in the United States (less so, unfortunately, among Chinese startups like Kimi, who I'm afraid have released unaligned models into the wild). Meta's recent biosafety report is worrying (scroll down to the "Safety" section here - https://ai.meta.com/blog/introducing-muse-spark-ms )